(这是个大坑,不要用)基于余弦相似度的音轨特征匹配(听歌识曲)
更新:不要用!!!我发现有三个不同的歌被识别成了一个,他们的重音部分都差不多,但是其他部分的声音完全不同,也被识别成了一首歌
目录
[TOC]
目的: 输入两个文件夹,通过音轨特征判断两个文件夹中的音轨是否同一首歌,类似于听歌识曲
零、原理
1.理论
- 提取音频特征(MFCC、色度、频谱对比度、零交叉率、均方根能量),连接成一个特征向量。
- 计算余弦相似度:
$$ \begin{align} \href{https://en.wikipedia.org/wiki/Cosine_similarity}{Cosine Similarity} &= \frac{\mathbf{A} \cdot \mathbf{B}}{\left\|\mathbf{A}\right\| \left\|\mathbf{B}\right\|} \text{,(定义式)} \\ \nonumber\\[1ex] &= \frac{\mathbf{u} \cdot \mathbf{v}}{\left\|\mathbf{u}\right\| \left\|\mathbf{v}\right\|} \\ \nonumber\\[1ex] &= \frac{\left\|u\right\| \left\|v\right\| \cos(\theta)}{\left\|u\right\| \left\|v\right\|} \text{,(其中,} \theta \text{ 是向量 } \mathbf{u} \text{ 和 } \mathbf{v} \text{ 之间的夹角)} \\ \nonumber\\[1ex] \nonumber&= \cos(\theta) \\ \nonumber\\[1ex] \nonumber\because-1 &\leq \cos(\theta) \leq 1 \\ \nonumber\\[1ex] \therefore-1 &\leq \text{Cosine Similarity} \leq 1 \end{align} $$
故余弦相似度的结果范围是 [-1, 1]:
- 1:两个向量完全相似(即它们的方向完全一致)。
- 0:两个向量没有任何相似性(即它们正交,没有线性关系,夹角为 90°)。
- -1:两个向量完全相反(即它们的方向完全相反,是对立的,夹角为 180°)。
- 计算余弦距离:
$$ \text{Cosine Distance} = 1 - \text{Cosine Similarity} $$
余弦距离的结果范围是 [0, 2]:
- 当余弦相似度为 1 时,余弦距离为 1-1=0(完全相似)。
- 当余弦相似度为 -1 时,余弦距离为 1-(-1)=2(完全相反)。
- 当余弦相似度为 0 时,余弦距离为 1-0=1(正交,完全无相似性)。
余弦距离的值范围是 [0, 2],值越接近 0 表示越相似,越接近 2 表示越不同。
2.实际应用
而代码中直接可以调用cosine(u, v, w=None)获取到余弦距离(Cosine Distance),就不用自己手动带定义式了,现在需要将余弦距离(Cosine Distance)还原为余弦相似度(Consine Similarity):
$$ \begin{align} \because \text{Cosine Distance} &= 1 - \text{Cosine Similarity} \\ \therefore \text{Cosine Similarity} &= 1 - \text{Cosine Distance} \\ \because \text{Cosine Distance} &= 1 - \frac{u \cdot v}{\|u\|_2 \|v\|_2} \\ \therefore \text{Cosine Similarity} &= 1 - \left( 1 - \frac{u \cdot v}{\|u\|_2 \|v\|_2} \right) \\ \because \text{cosine(u, v, w=None)} &= 1 - \frac{u \cdot v}{\|u\|_2 \|v\|_2} \\ \therefore \text{Cosine Similarity} &= 1 - (1 - \text{cosine(u, v, w=None)}) \end{align} $$
由此得到标准的余弦相似度= 1 - (1 - cosine(u, v, w=None))
但是区间[-1,1]不是那么方便,现需要进行归一化,将其范围从 [-1, 1] 转换为 [0, 1],
$$ \begin{align} \because\text{Cosine Similarity} &\in [-1, 1] \\ \therefore\text{Cosine Similarity} + 1 &\in [0, 2] \\ \therefore\frac{\text{Cosine Similarity} + 1}{2} &\in \left[\frac{0}{2}, \frac{2}{2}\right] = [0, 1] \\ \therefore\text{Cosine Similarity (normalized)} &= \frac{\text{Cosine Similarity} + 1}{2} \in [0, 1] \\ \therefore\text{Cosine Similarity (normalized)} &= \frac{[1 - (1 - \text{cosine(u, v, w=None)})] + 1}{2} \\ &= \frac{[1 - 1 + \text{cosine(u, v, w=None)}] + 1}{2} \\ &= \frac{\text{cosine(u, v, w=None)} + 1}{2} \end{align} $$
所以余弦相似度归一化后的公式就是:
$$ \text{Cosine Similarity (normalized)} = \frac{\text{cosine(u, v, w=None)} + 1}{2} $$
• 1:表示两个向量之间的 相似度最大,方向完全一致,完全相似。
• 0:表示两个向量之间 完全不相似,即它们的方向完全相反(余弦相似度为 -1)。
• 0.5:表示两个向量 正交,即它们的方向是垂直的(余弦相似度为 0)。这意味着它们之间 没有直接的线性关系,但并不意味着完全无关;它们在某些情况下可能仍然有一定的间接关系。
注:代码中当时偷懒没有化简,直接用的:
$$ \frac{[1 - (1 - \text{cosine(u, v, w=None)})] + 1}{2} $$
一、简单版(仅用MFCC,基本也够用了)
代码:
import os
import librosa
import numpy as np
from scipy.spatial.distance import cosine
SUPPORTED_FORMATS = (".mp3", ".wav", ".flac", ".ogg", ".aac", ".m4a")
def extract_features(audio_path):
"""
提取音频特征,返回MFCC的均值作为特征向量。
"""
try:
y, sr = librosa.load(audio_path, sr=None, mono=True)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20)
mfcc_mean = np.mean(mfcc, axis=1)
return mfcc_mean
except Exception as e:
print(f"Error processing {audio_path}: {e}")
return None
def build_feature_database(audio_folder):
"""
构建音频特征数据库,返回字典形式 {文件名: 特征向量}
"""
database = {}
for file in os.listdir(audio_folder):
if file.lower().endswith(SUPPORTED_FORMATS):
print(f"获取音频特征:{file}")
file_path = os.path.join(audio_folder, file)
features = extract_features(file_path)
if features is not None:
database[file_path] = features
return database
def find_best_match(target_database, reference_database):
"""
匹配 target 文件夹中所有音频到 reference 数据库中的最佳匹配。
返回每个文件的最佳匹配及相似度。
"""
results = []
for target_path, target_features in target_database.items():
best_match = None
best_similarity = 0 # 初始最差相似度为0
for ref_path, ref_features in reference_database.items():
cosine_distance_value = cosine(
target_features, ref_features
) # 计算余弦距离
# 归一化余弦相似度
normalized_similarity = (1 + (1 - cosine_distance_value)) / 2 # 归一化公式
if normalized_similarity > best_similarity:
best_match = ref_path
best_similarity = normalized_similarity
results.append((target_path, best_match, best_similarity))
return results
if __name__ == "__main__":
# 输入两个文件夹,自动匹配两个文件夹中音轨特征相同的两个音乐
target_folder = (
"/Users/someone/Desktop/未命名文件夹/网易云歌单" # 目标音频文件夹路径
)
reference_folder = "/Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack" # 参考音频文件夹路径
# 1. 构建特征数据库
print("正在构建目标音频特征数据库...")
target_database = build_feature_database(target_folder)
print(f"目标数据库构建完成,共包含 {len(target_database)} 首音乐")
print("正在构建参考音频特征数据库...")
reference_database = build_feature_database(reference_folder)
print(f"参考数据库构建完成,共包含 {len(reference_database)} 首音乐")
# 2. 匹配所有文件
print("正在匹配音频...")
match_results = find_best_match(target_database, reference_database)
# 3. 输出匹配结果
print("\n匹配结果:")
for target, best_match, similarity in match_results:
print(f"目标文件: {target}")
print(f"最佳匹配: {best_match}")
print(f"相似度: {similarity:.2f}\n")
with open("匹配结果.txt", "a") as f:
f.write(f"目标文件: {target}\n")
f.write(f"最佳匹配: {best_match}\n")
f.write(f"相似度: {similarity:.2f}\n\n")输出结果:
目标文件: /Users/someone/Desktop/未命名文件夹/网易云歌单/狩人ハンイットのテーマ.mp3
最佳匹配: /Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack/Therion, the Thief.flac
相似度: 1.00
目标文件: /Users/someone/Desktop/未命名文件夹/网易云歌单/治療のために.mp3
最佳匹配: /Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack/For Succor.flac
相似度: 1.00
目标文件: /Users/someone/Desktop/未命名文件夹/网易云歌单/ボスバトル2.mp3
最佳匹配: /Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack/Decisive Battle II.flac
相似度: 0.99二、复杂版(同时使用MFCC、色度、频谱对比度、零交叉率、均方根能量,并输出音频特征图像)
要获取的数据多了,故相比简单版的速度慢
代码:
import os
import hashlib
import librosa
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cosine
import platform
import locale
from tqdm import tqdm
SUPPORTED_FORMATS = (".mp3", ".wav", ".flac", ".ogg", ".aac", ".m4a")
RESULTS_DIR = "./结果"
IMAGE_SAVE_DIR = f"{RESULTS_DIR}/音频特征图像"
if not os.path.exists(IMAGE_SAVE_DIR):
os.makedirs(IMAGE_SAVE_DIR)
def generate_unique_filename_from_path(audio_path):
# 使用MD5哈希算法生成文件路径的哈希值
file_hash = hashlib.md5(audio_path.encode("utf-8")).hexdigest()
return f"{os.path.basename(audio_path)}-{file_hash}.png"
# 自动选择中文或英文字体以及图表内容
def set_font_and_labels():
system = platform.system()
user_locale = locale.getlocale()[0]
if user_locale.startswith("zh"): # 判断是否是中文环境
language = "zh"
else:
language = "en"
# 根据语言设置不同的字体和标题
if system == "Windows":
font = "Microsoft YaHei" if language == "zh" else "Arial"
elif system == "Darwin": # macOS
font = "STHeiti" if language == "zh" else "Arial"
elif system == "Linux":
font = "Noto Sans CJK" if language == "zh" else "Arial"
else:
font = "DejaVu Sans" # 默认字体
# 设置matplotlib的字体
plt.rcParams["font.family"] = font
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 根据语言设置标签
if language == "zh":
return {
"mfcc_matrix_title": "MFCC矩阵图 (梅尔频率倒谱系数矩阵图)",
"mfcc_matrix_xlabel": "时间",
"mfcc_matrix_ylabel": "MFCC 系数",
"mfcc_line_chart_title": "MFCC均值折线图 (梅尔频率倒谱系数均值折线图)",
"mfcc_line_chart_xlabel": "MFCC 系数编号",
"mfcc_line_chart_ylabel": "均值",
"chroma_matrix_title": "色度矩阵图 (Chroma Matrix)",
"chroma_matrix_xlabel": "时间",
"chroma_matrix_ylabel": "色度系数",
"chroma_line_chart_title": "色度均值折线图",
"chroma_line_chart_xlabel": "色度系数编号",
"chroma_line_chart_ylabel": "均值",
"spectral_contrast_matrix_title": "频谱对比度矩阵图 (Spectral Contrast Matrix)",
"spectral_contrast_matrix_xlabel": "时间",
"spectral_contrast_matrix_ylabel": "频谱对比系数",
"spectral_contrast_line_chart_title": "频谱对比均值折线图",
"spectral_contrast_line_chart_xlabel": "频谱对比系数编号",
"spectral_contrast_line_chart_ylabel": "均值",
"zero_crossings_matrix_title": "零交叉率图 (Zero Crossing Rate)",
"zero_crossings_matrix_xlabel": "时间",
"zero_crossings_matrix_ylabel": "零交叉率",
"rmse_matrix_title": "均方根能量图 (Root Mean Square Energy)",
"rmse_matrix_xlabel": "时间",
"rmse_matrix_ylabel": "能量",
}
else:
return {
"mfcc_matrix_title": "MFCC Matrix(Mel-frequency Cepstral Coefficients Matrix)",
"mfcc_matrix_xlabel": "Time",
"mfcc_matrix_ylabel": "MFCC Coefficients",
"mfcc_line_chart_title": "MFCC Mean Line Chart",
"mfcc_line_chart_xlabel": "MFCC Coefficient Index",
"mfcc_line_chart_ylabel": "Mean",
"chroma_matrix_title": "Chroma Matrix",
"chroma_matrix_xlabel": "Time",
"chroma_matrix_ylabel": "Chroma Coefficients",
"chroma_line_chart_title": "Chroma Mean Line Chart",
"chroma_line_chart_xlabel": "Chroma Coefficient Index",
"chroma_line_chart_ylabel": "Mean",
"spectral_contrast_matrix_title": "Spectral Contrast Matrix",
"spectral_contrast_matrix_xlabel": "Time",
"spectral_contrast_matrix_ylabel": "Spectral Contrast Coefficients",
"spectral_contrast_line_chart_title": "Spectral Contrast Mean Line Chart",
"spectral_contrast_line_chart_xlabel": "Spectral Contrast Coefficient Index",
"spectral_contrast_line_chart_ylabel": "Mean",
"zero_crossings_matrix_title": "Zero Crossing Rate",
"zero_crossings_matrix_xlabel": "Time",
"zero_crossings_matrix_ylabel": "Zero Crossing Rate",
"rmse_matrix_title": "Root Mean Square Energy",
"rmse_matrix_xlabel": "Time",
"rmse_matrix_ylabel": "Energy",
}
labels = set_font_and_labels()
def extract_features(audio_path):
"""
提取音频特征, 返回MFCC的均值作为特征向量。
同时保存MFCC特征的可视化折线图和矩阵图。
"""
try:
y, sr = librosa.load(audio_path, sr=None, mono=True)
# 提取不同的音频特征
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20)
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
spectral_contrast = librosa.feature.spectral_contrast(y=y, sr=sr)
zero_crossings = librosa.feature.zero_crossing_rate(y=y)
rmse = librosa.feature.rms(y=y)
# 计算各特征的均值
mfcc_mean = np.mean(mfcc, axis=1)
chroma_mean = np.mean(chroma, axis=1)
spectral_contrast_mean = np.mean(spectral_contrast, axis=1)
zero_crossings_mean = np.mean(zero_crossings, axis=1)
rmse_mean = np.mean(rmse, axis=1)
# 获取无扩展名的文件名
base_filename = os.path.splitext(os.path.basename(audio_path))[0]
# 保存特征的折线图和矩阵图到指定目录
unique_image_filename = generate_unique_filename_from_path(audio_path)
image_path = os.path.join(IMAGE_SAVE_DIR, unique_image_filename)
# 创建一个4行2列的子图布局,以显示8个图
fig, ax = plt.subplots(4, 2, figsize=(12, 16))
# 在图的顶部使用 `fig.text()` 显示文件名
fig.text(
0.5,
0.95,
f"Audio Features for {base_filename}",
ha="center",
fontsize=16,
weight="bold",
)
# 第一个特征:MFCC
# MFCC矩阵图(梅尔频率倒谱系数矩阵图)(Mel-frequency Cepstral Coefficients Matrix)
ax[0, 0].imshow(mfcc, cmap="viridis", aspect="auto", origin="lower")
ax[0, 0].set_title(f'{labels["mfcc_matrix_title"]}')
ax[0, 0].set_xlabel(labels["mfcc_matrix_xlabel"])
ax[0, 0].set_ylabel(labels["mfcc_matrix_ylabel"])
# MFCC均值折线图
ax[0, 1].plot(mfcc_mean, marker="o", linestyle="-", color="b")
ax[0, 1].set_title(labels["mfcc_line_chart_title"])
ax[0, 1].set_xlabel(labels["mfcc_line_chart_xlabel"])
ax[0, 1].set_ylabel(labels["mfcc_line_chart_ylabel"])
ax[0, 1].grid(True)
# 第二个特征:色度
# 色度矩阵图(Chroma Matrix)
ax[1, 0].imshow(chroma, cmap="coolwarm", aspect="auto", origin="lower")
ax[1, 0].set_title(f'{labels["chroma_matrix_title"]}')
ax[1, 0].set_xlabel(labels["chroma_matrix_xlabel"])
ax[1, 0].set_ylabel(labels["chroma_matrix_ylabel"])
# 色度均值折线图
ax[1, 1].plot(chroma_mean, marker="o", linestyle="-", color="r")
ax[1, 1].set_title(labels["chroma_line_chart_title"])
ax[1, 1].set_xlabel(labels["chroma_line_chart_xlabel"])
ax[1, 1].set_ylabel(labels["chroma_line_chart_ylabel"])
ax[1, 1].grid(True)
# 第三个特征:频谱对比度
# 频谱对比度矩阵图(Spectral Contrast Matrix)
ax[2, 0].imshow(spectral_contrast, cmap="magma", aspect="auto", origin="lower")
ax[2, 0].set_title(f'{labels["spectral_contrast_matrix_title"]}')
ax[2, 0].set_xlabel(labels["spectral_contrast_matrix_xlabel"])
ax[2, 0].set_ylabel(labels["spectral_contrast_matrix_ylabel"])
# 频谱对比度均值折线图
ax[2, 1].plot(spectral_contrast_mean, marker="o", linestyle="-", color="g")
ax[2, 1].set_title(labels["spectral_contrast_line_chart_title"])
ax[2, 1].set_xlabel(labels["spectral_contrast_line_chart_xlabel"])
ax[2, 1].set_ylabel(labels["spectral_contrast_line_chart_ylabel"])
ax[2, 1].grid(True)
# 第四个特征:零交叉率
# 零交叉率矩阵图
ax[3, 0].plot(zero_crossings[0], marker=".", linestyle="-", color="orange")
ax[3, 0].set_title(f'{labels["zero_crossings_matrix_title"]}')
ax[3, 0].set_xlabel(labels["zero_crossings_matrix_xlabel"])
ax[3, 0].set_ylabel(labels["zero_crossings_matrix_ylabel"])
ax[3, 0].grid(True)
# 第五个特征:均方根能量
# 均方根能量矩阵图
ax[3, 1].plot(rmse[0], marker=".", linestyle="-", color="purple")
ax[3, 1].set_title(f'{labels["rmse_matrix_title"]}')
ax[3, 1].set_xlabel(labels["rmse_matrix_xlabel"])
ax[3, 1].set_ylabel(labels["rmse_matrix_ylabel"])
ax[3, 1].grid(True)
# 保存为图片
plt.tight_layout()
plt.subplots_adjust(
top=0.88, hspace=0.4, wspace=0.2
) # top是上边距, hspace是子图上下间距, wspace是子图左右间距
plt.savefig(
image_path, dpi=100
) # dpi默认是100,调大了图片变清楚,但是生成和查看变慢
plt.close()
# 将所有特征均值组合成一个特征向量, 便于后续匹配
all_features = np.concatenate(
[
mfcc_mean,
chroma_mean,
spectral_contrast_mean,
zero_crossings_mean,
rmse_mean,
]
)
return all_features, image_path
except Exception as e:
print(f"Error processing {audio_path}: {e}")
with open(f"{RESULTS_DIR}/错误日志.log", "a") as log_file:
log_file.write(f"Error processing {audio_path}: {e}\n")
return None, None
def build_feature_database(audio_folder, output_file):
"""
构建音频特征数据库, 返回字典形式 {文件名: (特征向量, 图像文件路径)}
"""
database = {}
files = [
file
for file in os.listdir(audio_folder)
if file.lower().endswith(SUPPORTED_FORMATS)
]
os.makedirs(os.path.dirname(output_file), exist_ok=True)
with open(output_file, "a") as f: # 追加模式写入文件
for file in tqdm(files, desc="构建参考音频特征", unit="音频"):
tqdm.write(f"获取音频特征: {os.path.abspath(file)}")
file_path = os.path.join(audio_folder, file)
features, image_path = extract_features(file_path)
if features is not None:
database[file_path] = (features, image_path)
f.write(f"音频文件: {file_path}\n")
f.write(f"特征向量: {features.tolist()}\n\n")
return database
def find_best_match(target_database, reference_database):
"""
匹配 target 文件夹中所有音频到 reference 数据库中的最佳匹配。
返回每个文件的最佳匹配及相似度。
参数:
- target_database: dict, key为文件路径,value为一个元组(特征向量,图片)
- reference_database: dict, key为文件路径,value为一个元组(特征向量,图片)
返回:
- results: list, 包含每个目标文件的最佳匹配及相似度(目标路径,最佳匹配路径,相似度,目标图片)
"""
results = []
for target_path, (target_features, target_image) in target_database.items():
best_match = None
best_similarity = 0 # 初始最差相似度为0
for ref_path, (ref_features, _) in reference_database.items():
cosine_distance_value = cosine(
target_features, ref_features
) # 计算余弦距离
# 归一化余弦相似度
normalized_similarity = (1 + (1 - cosine_distance_value)) / 2
if normalized_similarity > best_similarity:
best_match = ref_path
best_similarity = normalized_similarity
results.append((target_path, best_match, best_similarity, target_image))
return results
if __name__ == "__main__":
# 输入两个文件夹, 自动匹配两个文件夹中音轨特征相同的两个音乐
target_folder = (
"/Users/someone/Desktop/未命名文件夹/网易云歌单" # 目标音频文件夹路径
)
reference_folder = "/Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack" # 参考音频文件夹路径
# 1. 构建特征数据库
print("正在构建目标音频特征数据库...")
target_database = build_feature_database(
target_folder, f"{RESULTS_DIR}/特征向量/目标音频.txt"
)
print(f"目标数据库构建完成, 共包含 {len(target_database)} 首音乐")
print("正在构建参考音频特征数据库...")
reference_database = build_feature_database(
reference_folder, f"{RESULTS_DIR}/特征向量/参考音频.txt"
)
print(f"参考数据库构建完成, 共包含 {len(reference_database)} 首音乐")
# 2. 匹配所有文件
print("正在匹配音频...")
match_results = find_best_match(target_database, reference_database)
# 3. 输出最佳匹配结果
best_match_image = None
for target_path, best_match, best_similarity, target_image in match_results:
for ref_path, (_, ref_image) in reference_database.items():
if ref_path == best_match:
best_match_image = ref_image
break
print(f"目标文件: {target_path}")
print(f"最佳匹配: {best_match}")
print(f"相似度: {best_similarity:.2f}")
print(f"目标文件的特征图像: {os.path.abspath(target_image)}\n")
print(f"最佳匹配文件的特征图像: {os.path.abspath(best_match_image)}\n")
with open("./结果/匹配结果.log", "a") as f:
f.write(f"目标文件: {target_path}\n")
f.write(f"最佳匹配: {best_match}\n")
f.write(f"相似度: {best_similarity:.2f}\n")
f.write(f"目标文件的特征图像: {os.path.abspath(target_image)}\n")
f.write(f"最佳匹配文件的特征图像: {os.path.abspath(best_match_image)}\n\n")输出结果:
目标文件: /Users/someone/Desktop/未命名文件夹/网易云歌单/狩人ハンイットのテーマ.mp3
最佳匹配: /Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack/Therion, the Thief.flac
相似度: 1.00
目标文件的特征图像: /Users/someone/Desktop/未命名文件夹/结果/音频特征图像/狩人ハンイットのテーマ.png
最佳匹配文件的特征图像: /Users/someone/Desktop/未命名文件夹/结果/音频特征图像/Therion, the Thief.png
目标文件: /Users/someone/Desktop/未命名文件夹/网易云歌单/治療のために.mp3
最佳匹配: /Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack/For Revenge.flac
相似度: 0.99
目标文件的特征图像: /Users/someone/Desktop/未命名文件夹/结果/音频特征图像/治療のために.png
最佳匹配文件的特征图像: /Users/someone/Desktop/未命名文件夹/结果/音频特征图像/For Revenge.png
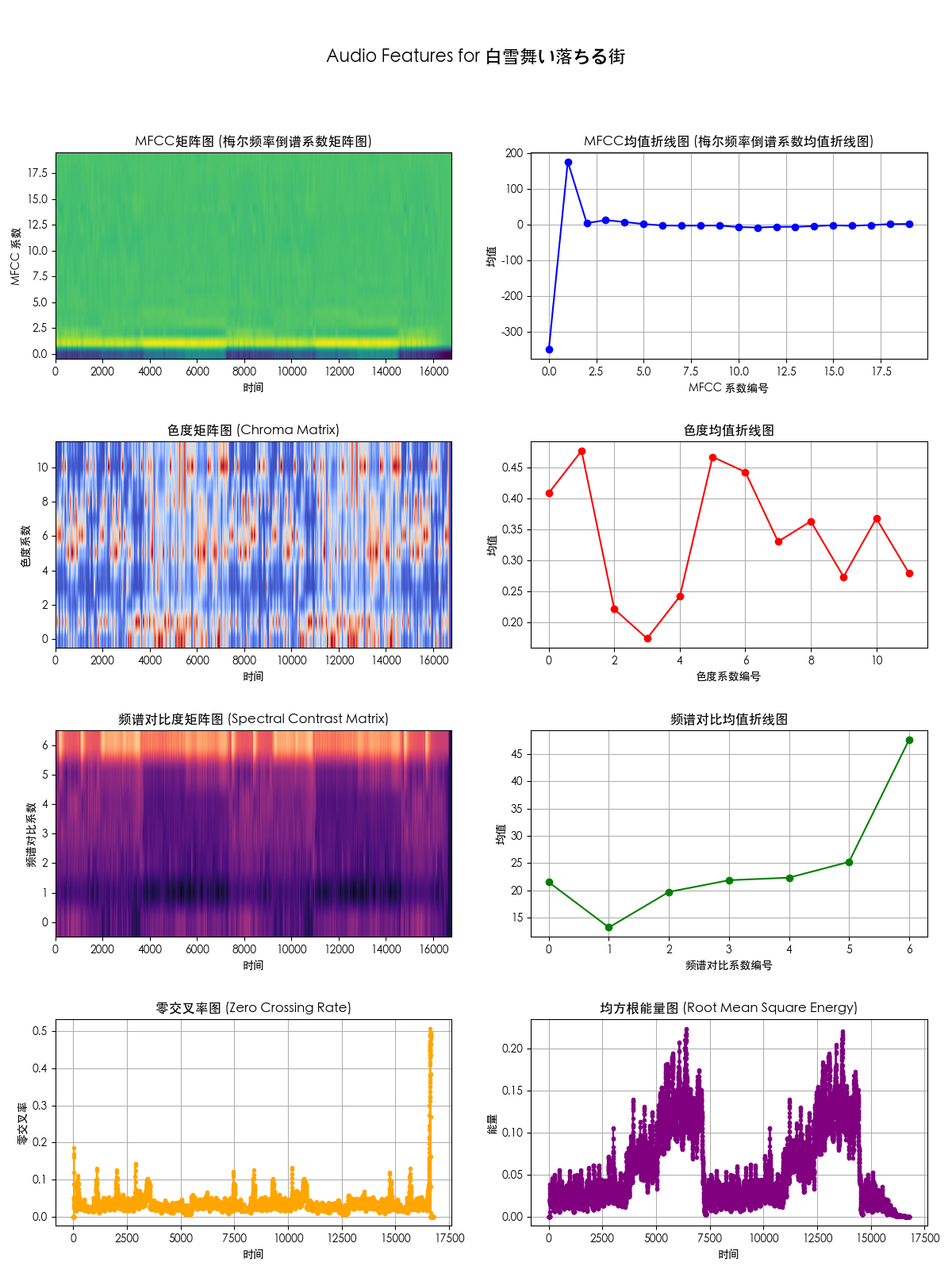
目标文件: /Users/someone/Desktop/未命名文件夹/网易云歌单/白雪舞い落ちる街.mp3
最佳匹配: /Users/someone/Downloads/Yasunori Nishiki/OCTOPATH TRAVELER Original Soundtrack/Town Veiled in White.flac
相似度: 1.00
目标文件的特征图像: /Users/someone/Desktop/未命名文件夹/结果/音频特征图像/白雪舞い落ちる街.png
最佳匹配文件的特征图像: /Users/someone/Desktop/未命名文件夹/结果/音频特征图像/Town Veiled in White.png可视化结果:
白雪舞い落ちる街.mp3的特征图:
Town Veiled in White.falc的特征图:
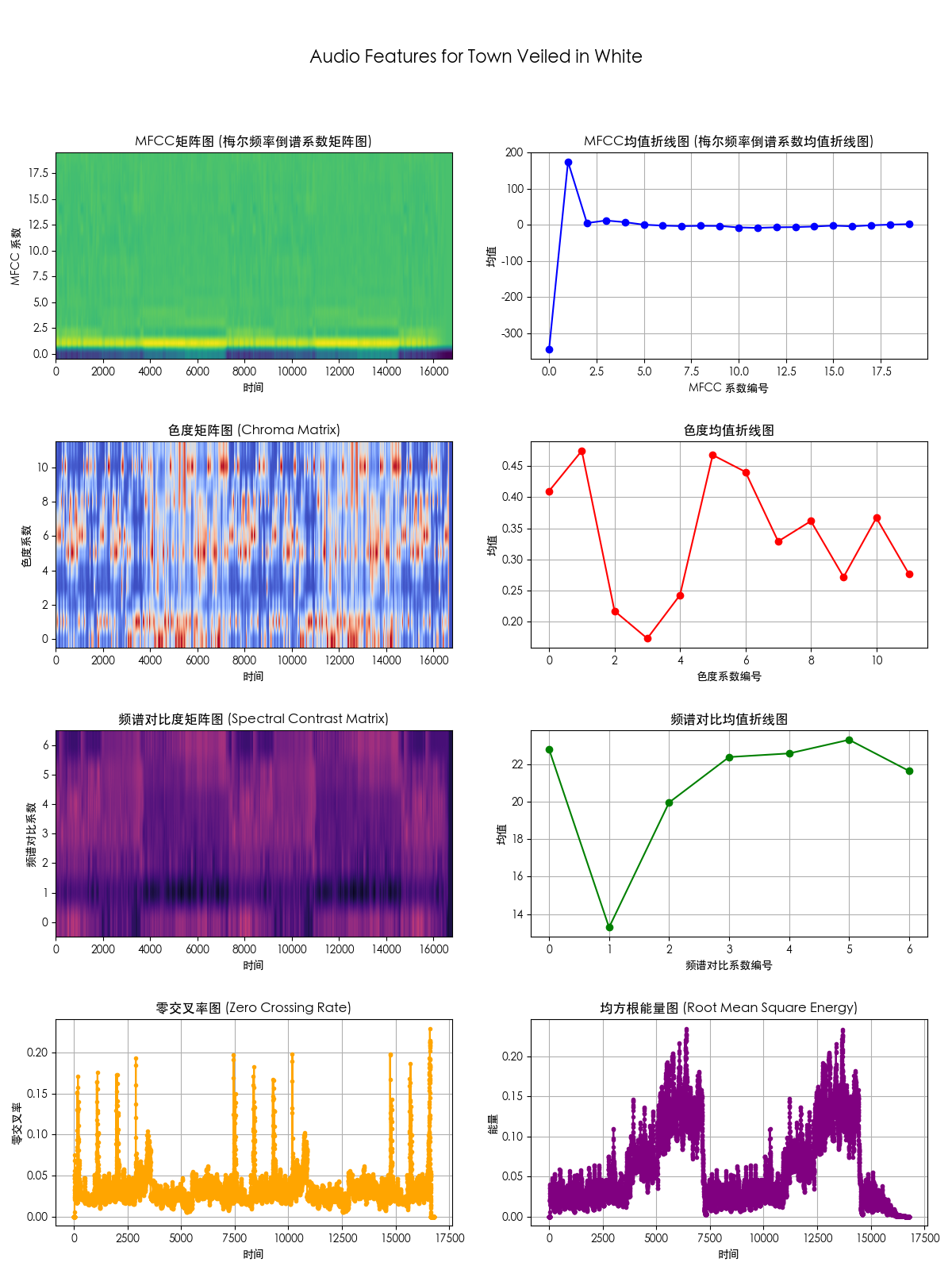
可以看出基本一样,故判断是同一首歌曲
